
Had a bit of a problem recently and it fit perfectly with my previous post about character encodings. Whereas in my previous post I talked a lot about php, in this one I use JavaScript/NodeJS and Bash/ZSH, though not so intensely.
The problem
The application we’re working on pulls mission-critical information from an API. This information is then stored in the a database and used for Customer Support, shipping, after-sale services, so on and so forth. Basically, it’s really important information.
Now, as it usually happens, some of the systems that make the entire operation are a bit.. outdated. Nothing wrong with that. But when doing our integration tests, we noticed that what in the API looked like1…
Gyönyörű Bögre
On the database was then showing up as…
Gy�ny�r? B�gre
So what’s going on here?
If you first read my first blog post, you’ll have some intuition of what’s happening. But since you’re lazy, and so am I, then let’s break it down.
- The original data comes from an API source. The text looks OK.
- That data is retrieved and then stored in a database for the client. The text is garbled or otherwise unreadable.
- The client is not happy.
As I normally do, I went to look at the guts of the monster. What I found was mostly what I was expecting.
First I checked the Content Type of the API2.
The line Content-Type: application/json; charset=utf-8 is pretty explicit telling us that our contents are in UTF-8.
I suspected that already but it never hurts to check.
So our source data is coming in UTF-8. Upon checking the database charset, it showed up as ISO 8859-1, also known (perhaps incorrectly) as Latin 1. It’s a character set from the late 80’s intended to group most of the European characters, and since I live right in the middle of Europe, this makes sense.
However, it’s unfortunate, because I’m storing bytes in the database that are meant to be read as UTF-8, and the database (and the database clients) will spit them back at me thinking it’s ISO-8859-1. Hence, unrecognizable characters: �.
If you still don’t know what’s going on, let’s look at the hexdump of that particular string.
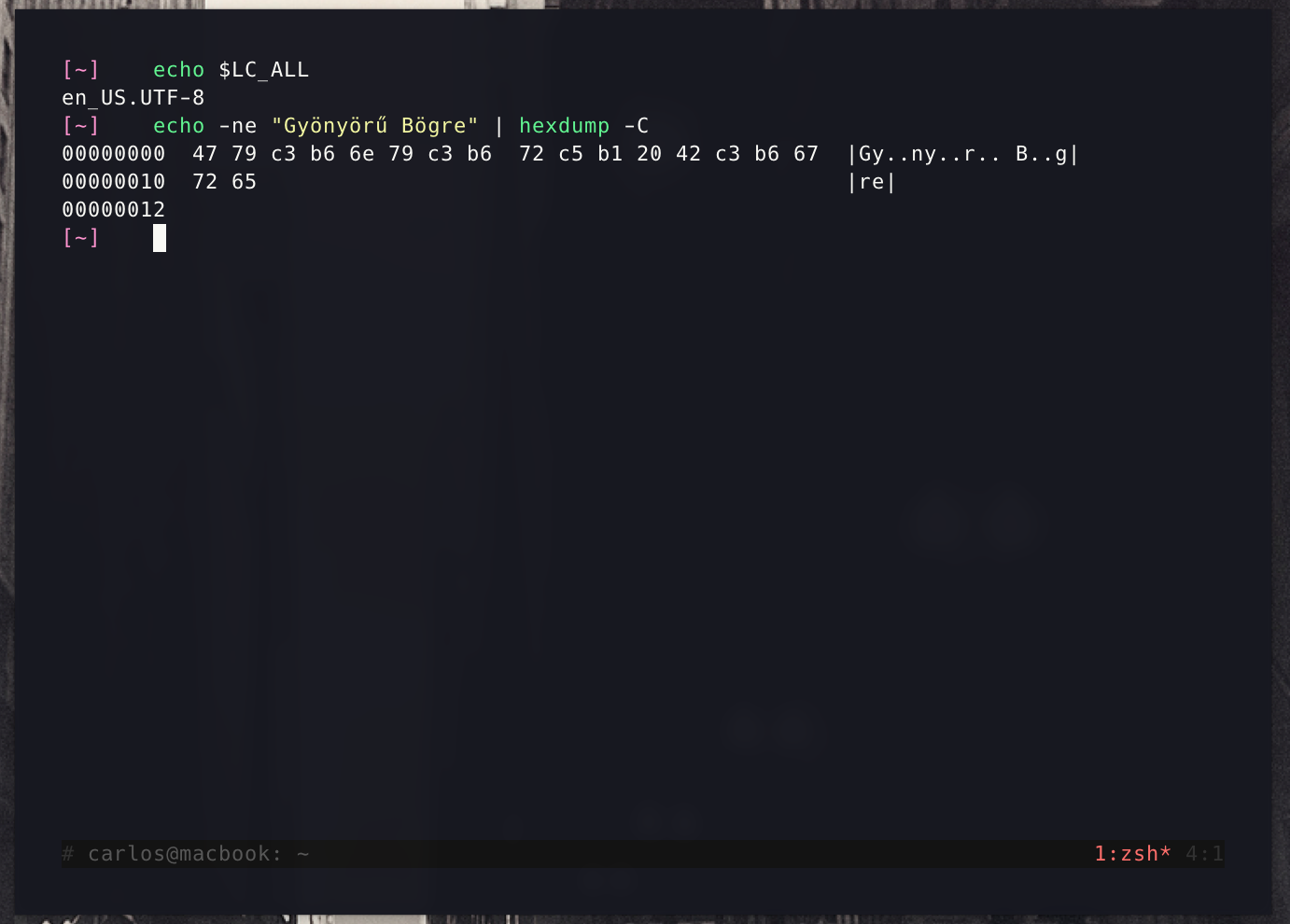
The first column of the hexdump output is the byte offset. We’re interested in the other values for now.
If you look closely, hexdump is even nice enough to tell us which glyphs are multibyte3, denoted by .. (this means two bytes, try more glyphs on your own :D). You can read then the matching glyphs to their UTF-8 representation. So G = 0x47, y = 0x79, ö = 0xC3 0xB6, .., ű = 0xC5 0xB1, .., and yeah, you get it.
Now these bytes are stored in the database, but the database thinks these are ISO-8859-1 values. Now the thing is that this encoding is single-byte encoding, we’re not going to be reading by boundaries like we did in UTF-8, but byte by byte. So it reads… 0x47 = G, 0x79 = y, 0xC3 = ?, …, and it breaks.
The “solution”
So we presented the problem and one of the devs said: “I can fix it!”, and went ahead to add the lines…
Fair enough, right?
Not so fast
When we got the output, it showed up as something like
Gyönyör? Bögre
What the hell is that ? still doing there?
At this point we’re all getting a little agitated.
The real solution
So what gives? iconv should have worked.
Right?
Well, no.
Just to quote the iconv manual page…
Convert encoding of given files from one encoding to another
So basically, if the letter ö in UTF-8 looks like ö = 0xC3 0xB6, in ISO-8859-1 it looks like ö = 0xF6. It makes sense, in UTF-8 it’s a multi-byte glyph, and in ISO-8859-1 it’s a single byte, just like it was intended. And satisfyingly enough, iconv did just that for us. But what about that weird-looking ű?
Well the table below is a nice illustration..
| Encoding | Byte representation |
|---|---|
| utf8(ű) | 0xC5 0xB1 |
| iso8859(ű) | ? |
The letter ű doesn’t exist in ISO-8859-14, so iconv can’t map it to anything.
This is what a lot of people get wrong about iconv, it’s not a magic solution to your character problems. And really, if we had used a more robust iconv library like node-iconv, then we would’ve received a proper error message. Nothing wrong with iconv-lite, in fact they claim it’s faster, and the source code is quite easy to follow and make sense of it. However it suppresses this message.
Folding characters
So the solution that we opted for is a bit less known, albeit useful.
It’s called “folding” although I guess you could call it “mapping”, or whatever you want. It relies on mapping a character5 to whatever is “closest” either in shape or meaning. So we went ahead and implemented a fold for it. I called it foldToISO() because I’m simply not creative enough.
When you foldToISO, you’re ensuring (at least in most cases), that you’re going to be mapping to a character that does exist in the “receiving” end encoding, in this case ISO-8859-1.
This way, we say “map ű to u”, because we know that u is in ISO-8859-1, and then therefore iconv can handle it accordingly. It won’t have to think much about it, though, because in both cases it’s u = 0x756.
Now, when we executed that and looked at the database, we saw..
Gyönyöru Bögre
And since there were no broken characters and the client understood the limitation, everyone was happy :)
Practical example
So let’s try to think about when folding characters might come in useful 🤔.
I really like Ólafur Arnalds, and one of my favorite songs from him is “Þú ert jörðin”. I listen to a lot of Spotify, and use the search bar a lot. Due to my travelling and living in so many places, I use a Spanish ISO keyboard layout, and I don’t have all the characters available to search for my song… “Þú ert jörðin”. If I were to search for it, I would type what I can make out of that.. something like “ert jordin”, for example7, and this works!
Well, I have no idea how Spotify does search, but let’s assume that they use Elasticsearch. Now you don’t have to know much about it, but it’s built on top of Apache Lucene, which is a text search engine.
Now Lucene stores text in UTF-8, meaning that it supports all the characters of that song that I desperately wanna listen to. No problem for them there. I only typed “ert jordin”, however, so how can they successfully return my song?
Well, I’m no big-city developer, but if it were me, I would fold the shit out of that string into ASCII values, and make a lookup on an inverted index.
And if we try to fold “Þú ert jörðin” to ASCII, we get “THu ert jordin”… how grand!
Yeah…
It just so happens that Lucene comes with an AsciiFoldingFilter right out of the box.
So there you go…, problem mildly-solved.. I mean, you still have to think about how to store all that, and how to build it, etc etc etc :)
Achtung!
Folding characters does not mean that you convert the byte representation from one charset to another, you change the actual glyph within the same charset. This is why in the last gist up there we’re still doing iconv.encode. Except that now we can safely do this conversion.
The result
Well, feast your eyes on this… internally, the results looked like
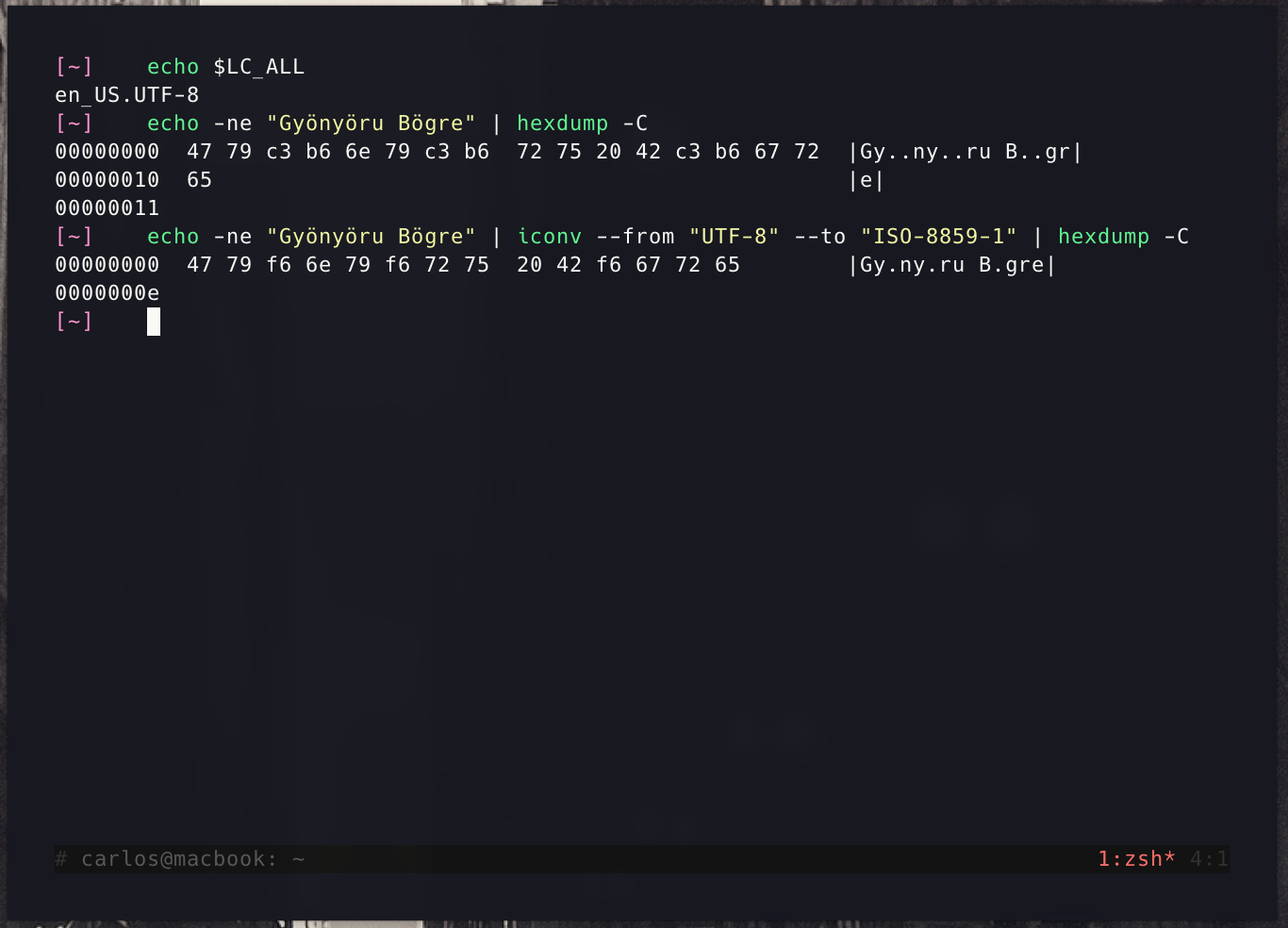
It’s also evident that we’re now saving a few bytes. If you care about that. I think that if a client has TBs of information, then yes, they probably do :)
iconv and the //TANSLIT and //IGNORE flags
So if you’ve ever used iconv to some extent, you’re probably thinking “Yo! What about the //TRANSLIT flag? Doesn’t that do the folding for you already?”.
And you’re right, it “transliterates” your text. However, it’s not very well documented, not widely supported by most of the iconv clients. In my experience, using //TRANSLIT has yielded more problems than it has solved.
So what about //IGNORE? Well, you’re ignoring the problem altogether, so it’s simply bad practice :)
Lessons
iconvis awesome. But it’s badly documented. And misunderstood, pooriconv:(iconvis not a magic wand.- “Folding” has its advantages.
- The world is not Unicode.
Considerations
- I don’t know if I’ll be writing more on character sets, because I think that two blog posts about this has exhausted the subject a little bit.
- The
LC_ALLenvironment variable can give you issues when running some shell programs. A quick-and-dirty solution is to prefix the variable definition before the execution of a certain program. Like so…$ LC_ALL=C myprogram --flag=whatever. - Have you learned your encoding?
- Soon enough I’ll be posting the code that does the folding :)
{kind=link}
Resources and more reading
Listening to…
Actually on vinyl, but here’s the Spotify link :)
Thanks for the gift :)
Amendments
Any and all amendments to this post can be found here.
Footnotes
I’m obviously not going to use real data. This is fake data. In Hungarian it means “Beautiful cup”. I like cups. I have a few that are really nice.↩︎
Again, I’m using fake data for this post.↩︎
But you know that
UTF-8is a variable-length encoding already, because you read that first post. Right?↩︎https://en.wikipedia.org/wiki/ISO/IEC_8859-1, look at the “Missing characters” section for Hungarian.↩︎
In most “fold” implementations, you’ll find people folding per
char, instead of pergrapheme-cluster. In most JavaScript implementations, you’ll find that acharis 16-bit. Now this leaves the door open forUTF-16andUCS-2. If you’re interested in that Matthias Bynens wrote a great post about it, and I would also advise you to follow him. He’s pretty smart!↩︎According to Wikipedia you can also use the letters
ÛorÜ. In these cases, we can see that inUTF-8these look likeÛ = 0xC3 0x9BandÜ = 0xC3 0x9C, whereas inISO-8859-1they look likeÛ = 0xDBandÜ = 0xDC.↩︎Try it for yourself, try different combinations, etc :D↩︎